The purpose of this lab is to gain knowledge and skills in measuring and identifying change of LULC over a specified time period utilizing remotely sensed imagery. I will be conducting a quick qualitative change detection method along with a quantifying post-classification changed detection method. Additionally, I will be creating a model which will allow me to display the result of the change detection on a map.
Methods
All of the following step were performed in Erdas Imagine 2015.
Change detection using Write Function Memory Insertion
Utilizing Write Function Memory Insertion is a simple yet powerful method to detect changes between images of the same area from different time frames. The analyst simply opens the near-infrared bands from the two dates of imagery in the red, green, and blue color guns. The pixles within the images which have changed will be displayed as a different color against those which remained the same.
For this section of the lab I utilized images of Eau Claire and surrounding counties provided to me by my professor Dr. Wilson. I opened the an image containing the red band (band 3) from 2011 and then 2 images of near-infrared band of the same area from 1991. The last step was to layer stack the images together. I opened the layer stacked image in a viewer in Erdas to see the results (Fig. 1).
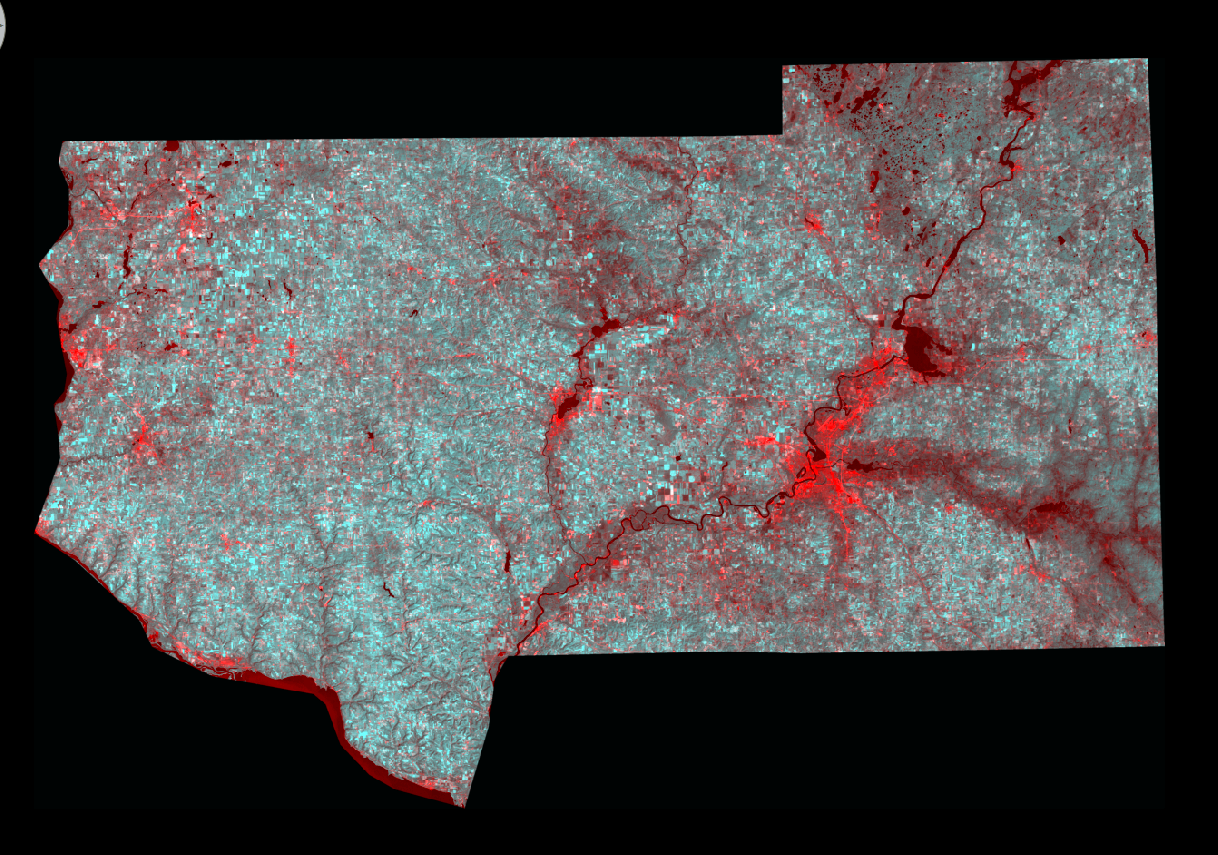 |
| (Fig. 1) Results from performing Write Function Memory Insertion. The bright red areas are where change has occurred in the images between the two dates. |
Post-classification comparison change detection
For this section of the lab I will be conduction change detection of the Milwaukee Metropolitan Statistical Area (MSA) between 2001 and 2011. I was provided previously classified images from my professor Dr. Wilson.
The first objective for this section of the lab is to quantify the change which has occurred in the Milwaukee MSA in hectares between the classified image from 2001 and classified image from 2011. I brought the two image in to separate viewers in Erdas (Fig. 2).
 |
| (Fig. 2) 2001 classified image (Left) and 2011 classified image (Right) of the Milwaukee MSA in Erdas. |
 |
| (Fig. 3) Histogram values input in to Excel spreadsheet converted to Hectares. |
 |
| (Fig. 4) Percent change between the 2001 and 2011 image of the Milwaukee MSA area. |
The next step for this section of the lab is to develop a From-to change map from the two images. I created a model to detect the change between the two images. Within the model I will also create an image which displays the areas which have changed for the following classes.
- Agriculture to urban/built-up
- Wetlands to urban/built-up
- Forest to urban/built-up
- Wetlands to agriculture
- Agriculture to bare soil
I will be utilizing the Wilson-Lula algorithm to detect the change and create the display images. The first step is to separate the individual classes using an "either or" statement. The either or statement will create a image containing one class only, such as, agriculture areas and nothing else. Each separate class is grouped together to match the above list of five comparative classes. The "either or" images was put into a temporary raster to save on storage space within the computer. The next step was to use a Bitwise function to shows the areas which changed from one LULC class to another. The output from the function can be input on a map to display the areas of change.
 |
| (Fig 5) Model utilizing the Wilson-Lula algorithm. |
Results
 |
| (Fig. 6) Map displaying the LULC change in the Milwaukee MSA area. |
Homer, C., Dewitz, J., Fry, J., Coan, M., Hossain, N., Larson, C., Herold, N., McKerrow, A., VanDriel, J.N., and Wickham, J. 2007. Completion of the 2001 National Land Cover Database for the Conterminous United States.Photogrammetric Engineering and Remote Sensing, Vol. 73, No. 4, pp 337-341.
Xian, G., Homer, C., Dewitz, J., Fry, J., Hossain, N., and Wickham, J., 2011. The change of impervious surface area between 2001 and 2006 in the conterminous United States. Photogrammetric Engineering and Remote Sensing, Vol. 77(8): 758-762.